
Research
We have broad research interests across machine learning and its applications. Most applications can be summarized under the umbrella of computational sustainability, a strongly interdisciplinary research area that uses machine learning approaches to address sustainability challenges in Aotearoa and worldwide. For example, our researchers develop models that predict the environmental fate of pollutants, analyse bat calls to track environmental pollution, or analyse air pollution sensor data sets.

Computational Sustainability
Computational sustainability is an interdisciplinary field of sustainability research, including applied science about the research in sustainable solutions and their implementation. Machine Learning and Data Mining is at the center of this research area linking together diverse application areas such as environmental sciences, atmospheric science, agriculture, or social science.
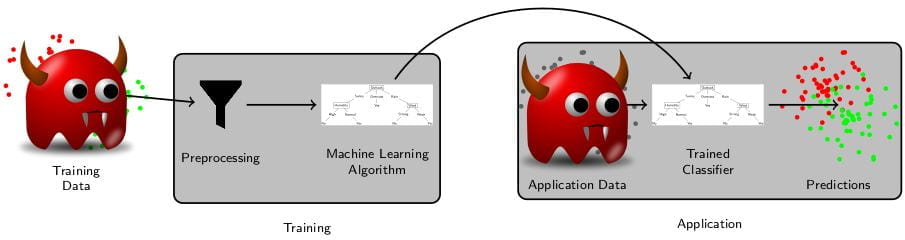
Adversarial Learning
Adversarial learning aims to identify weaknesses in machine learning models. The goal is to identify potential problems that cannot be found using traditional evaluation using test sets. It has been used successfully in a wide range of applications, typically focused on a specific model or domain. In image classification, methods have been developed to fool models that recognize traffic signs by rather simple modifications of pictures. Another direction of adversarial learning aims to identify examples that could break or improve the training of the model if that example would be added to the training.
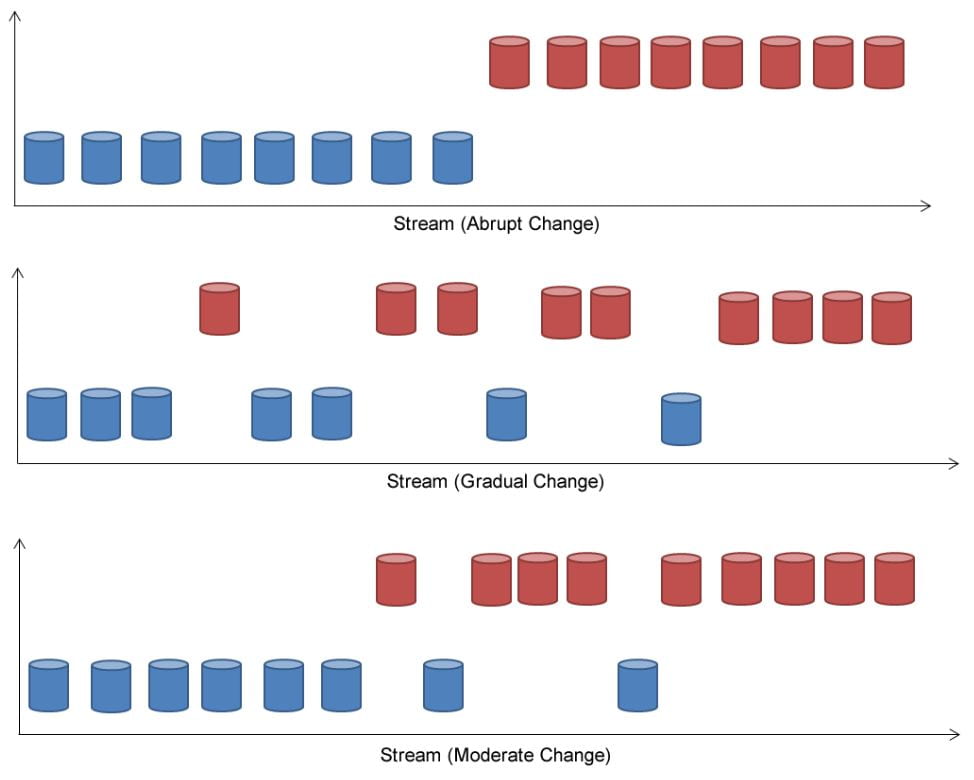
Data Streams
Data Stream Mining extracts knowledge from continuous data which arrives into the system in a stream. Data stream sources consist of IoT sensors, through to air pollution sensors, health records. In this area of research, we are developing new and novel predictive techniques that can deal with data that is evolving and changing on a continuous basis. We are interested in continued adaptation of our model, to provide an accurate prediction in real time.
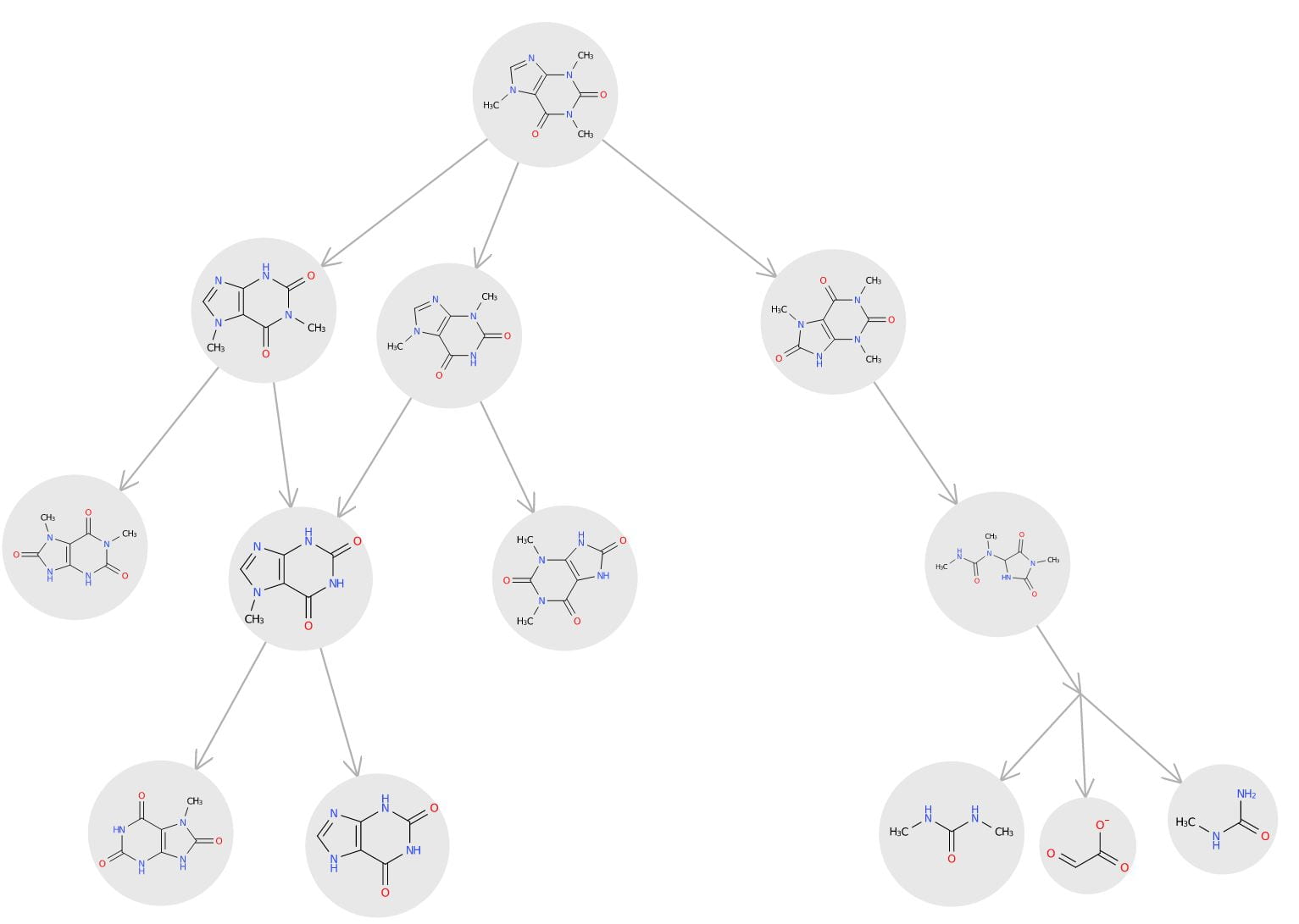
Cheminformatics
Cheminformatics is an interdisciplinary research field at the intersection of chemistry and computer science. It strongly relies on machine learning methods to address challenges in chemistry. Our research addresses a wide range of applications such as prediction of metabolic pathways, predictive toxicology, and analysis of atmospheric chemistry data sets.
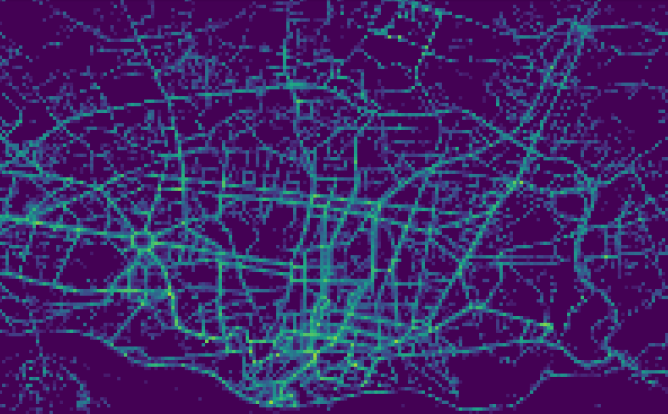
Spatio-temporal Data Mining
The prevalence of location positioning devices such as GPS have made huge amount of geo-tagged data available. Spatio-temporal data mining is to automatically uncover latent patterns from data associated with GPS coordinates over time. This research area links to various of applications including geographical topic analysis, local event detection, location recommendations and traffic prediction.
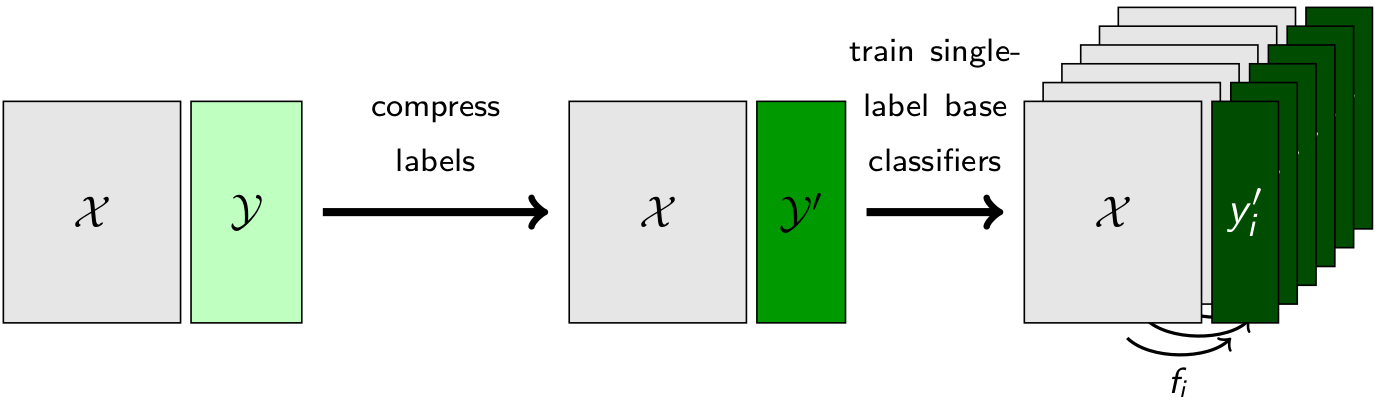
Multi-Label Classification
Multi-label classification targets the prediction of multiple interdependent and non-exclusive binary target variables. Transformation-based algorithms transform the data set such that regular single-label algorithms can be applied to the problem. A special type of transformation-based classifiers are label compression methods, that compress the labels and then mostly use single label classifiers to predict the compressed labels.

Bias
While the awareness for discrimination biases based on genders or ethnicities has grown a lot in recent years, especially in the context of fairness in Machine Learning, many datasets come with certain biases of which the researcher is not aware and hence uses to train sub-optimal models. Selection Bias identification and mitigation strategies, general enough to be a fixed component of every Machine Learning pipeline, are crucial to enable the researcher to improve the data quality by mitigating the bias instead of training a biased model.

Boolean Matrix Factorization
The goal of a Boolean matrix factorization is to represent a given Boolean matrix as a product of two or more Boolean factor matrices. It is a well-known and researched problem with a wide range of applications, e.g. in multi-label classification, clustering, bioinformatics, or pattern mining.