Defending machine learning models from adversarial attacks is an ongoing problem. No defence is completely immune to adversarial examples to date. Most existing approaches are tied to a specific machine learning model and struggle to preserve good performance on clean inputs. As a result, few adversarial defences have been deployed in real-world applications. There is the need for establishing a baseline for measuring the vulnerability of a classifier given its training data, so the user can have a better understanding of the potential threats from adversarial attacks.
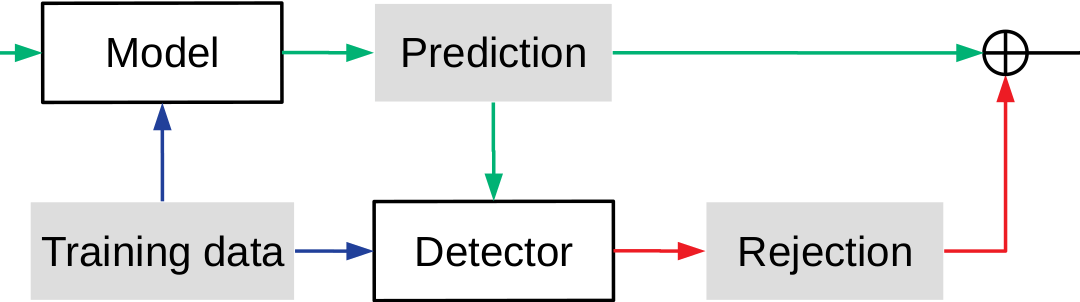
In the first year, I introduced the concept of black-box defences. It is a scenario where the defender has limited access to the model, modifying the parameters and retraining the model are not viable strategies. I provided a novel multi-stage black-box defensive framework inspired by the concept of Applicability Domain. By testing for applicability, reliability and decidability, this data-driven approach preserves the performance of the black-box model while effectively defending adversarial attacks. Through my analysis, I found this black-box approach performs equally well on blocking adversarial examples from various models.
I then expand on the existing algorithm and focus on explainable attacks and the defences. The objective is to establish a framework which can be used to evaluate the robustness of the data against unknown adversarial attacks given a machine learning model. By bounding the data and the model as a pair, this framework will identify the vulnerabilities within the pair, so the user can make a balanced decision between rejecting unforeseeable attacks and accuracy on the clean data in the model selection phase.