 Kia Ora!
Kia Ora!I am Katharina Dost, a PhD student in my second year with the School of Computer Science. My research topic is “Identification and Mitigation of Selection Bias” and I would like to use this post to talk about my research and my experiences, so read on!
Our world runs on data. We gather whatever we can and use it to answer a variety of questions. These can be something as simple as “What is the average age of my customers?” but also as critical as “Which treatment is best suited for my disease?”.
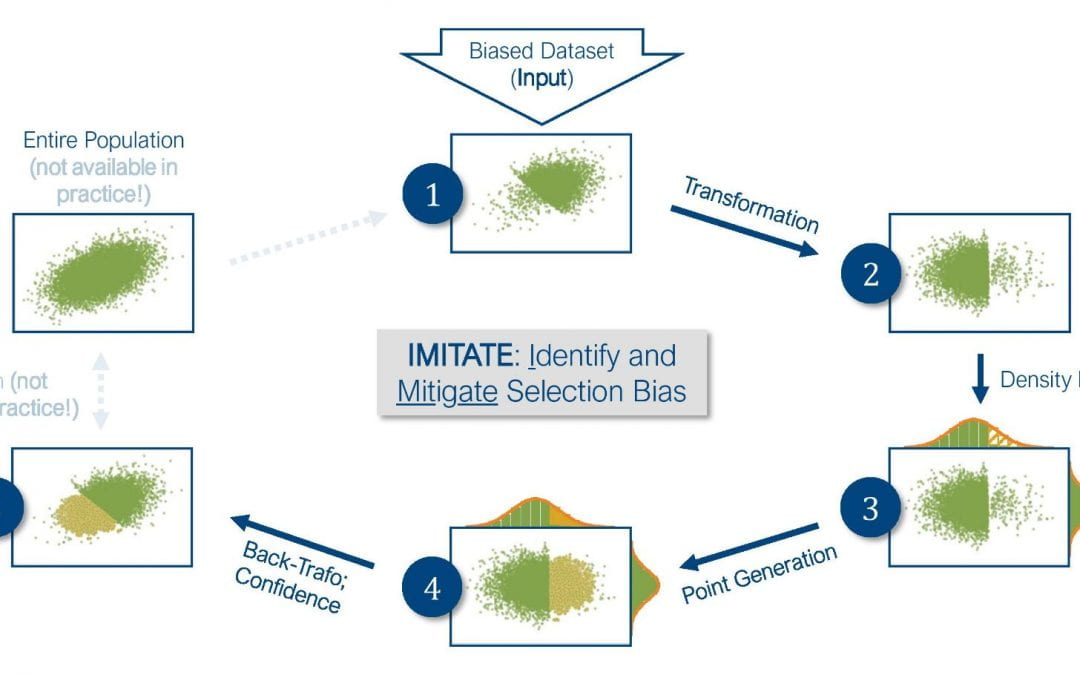
But the collected data often does not represent the entire population about which we would like to make assumptions. This is called Selection Bias, and it typically means that if we learn a model based on the obtained data, it won’t perform well on the entire population. For example, if we only observe birds in South-America, a classification model won’t be able to identify a Kiwi (neither the bird, nor the fruit, nor the person). The good news is: If you are aware of that bias or if you know what your entire population looks like, there are options. But if you assume that everything is fine or you simply don’t know your entire population, you will use the biased dataset and train a poorly performing model. Let’s be honest: who knows which customers buy at a shop? We might know the ones with a membership card, but that’s a biased subset!
I believe that there’s already some information on the entire population hidden in a biased dataset, and my research aims to uncover it and generate data to fix the bias. Therefore, I investigate the dataset’s distribution and search for flaws that point out where to generate data. I am aware that my solution will not work in all cases, but if it can reliably warn the user where it doesn’t work, we can use it as a fixed component in every Data Analysis or Machine Learning preprocessing step and achieve cleaner data as well as better models!
In order to achieve this goal, my days are mostly spent in front of the computer. On a good day, I have a great idea and implement as well as test it. But often enough, I don’t know how to move on or how to solve my problems. Then I spend the day searching the literature for solutions and inspiration or discuss my problem with my fellow researchers. Often, I also try to support my peers with their own problems as it always feels good to help and I learn about other cool topics and perspectives.
What I enjoy most about my research are the moments when suddenly something works after a long series of failures. From the outside, it might not always look like much, but for me every small step towards achieving my goal is exciting.
Of course, there are not only enjoyable moments when you are trying to push the boundaries of knowledge but also rather frustrating and challenging ones. These include research-related questions like “How can I break that huge problem into bite-sized chunks?”, “Is there a method I can use to solve my problem, or do I have to come up with my own solution?” or “Is my research worth being published?”, efficiency-related questions like “Is there a Python library for that?”, but also existential questions like “Am I at the right place here? Am I smart enough for a PhD?”.
For me personally, it always helps to first narrow challenges down to the exact problem, and if I did not already find a solution along the way, I talk to my supervisors or peers – someone will drop the right keyword to provide me with a new idea. It surprised me, but presenting my research to different audiences also helped me to believe in what I am doing and that it can have a true impact if I succeed.
If I could travel back in time and talk to my younger research self, I would tell myself to be less nervous about the decision to start a PhD – I chose the best supervisors I could have asked for (which is the crucial part of doing a successful PhD in my opinion!) and the University of Auckland is a great place to study.